
阅读app官方免费版是一款开源看小说软件,支持自定义网络书源,轻松导入各类书源,汇聚全网热门网文资源,一个应用即可畅读你喜爱的各类小说。
软件特色
1、支持自定义书源,用户可自行设置抓取规则,轻松提取网页小说内容,规则编写简单直观,软件内附详细说明文档。
2、书架界面提供列表与网格两种视图模式,自由切换,满足不同用户的浏览习惯。
3、书源规则全面支持搜索与发现功能,所有找书、看书流程均可高度自定义,找书更高效便捷。
4、可订阅任意感兴趣的内容,精准追踪更新,真正做到“想看什么就看什么”。
5、内置内容替换与净化功能,有效去除广告、无关文字,提升阅读纯净度。
6、兼容本地TXT、EPUB格式电子书,支持手动浏览与智能扫描,本地阅读同样流畅。
7、阅读界面高度可定制,包括字体、颜色、背景、行距、段距、加粗、简繁转换等,打造专属阅读体验。
8、提供多种翻页模式,如覆盖、仿真、滑动、滚动等,随心选择最舒适的翻页方式。
9、软件完全开源,持续迭代优化,全程无广告干扰,专注阅读本身。
怎么添加小说
1、打开阅读App,点击右上角的搜索图标。

2、在搜索框中输入想看的小说名称,例如“狂飙”。

3、App将自动列出所有包含“狂飙”的小说结果。
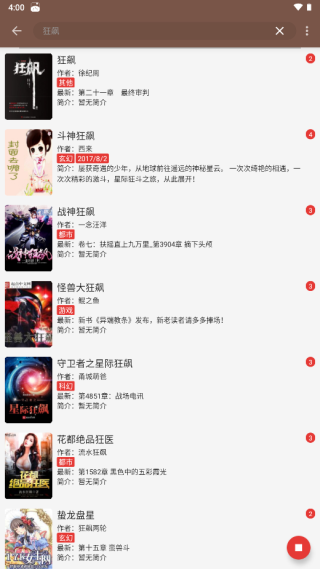
4、点击目标小说,选择“放入书架”即可完成收藏。

5、返回书架页面,即可看到刚刚添加的《狂飙》。
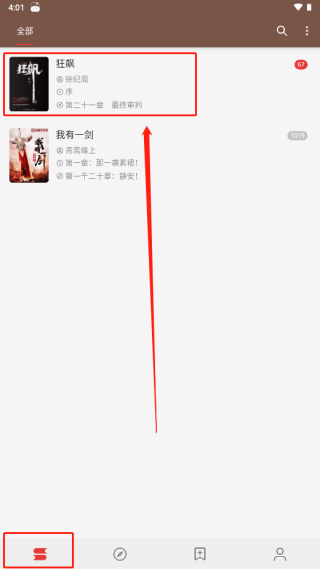
6、点击书名,立即开始阅读。

书源说明
1、书源规则基于HTML标签结构,如class、id、tag等元素进行内容定位。
2、编写规则前需先查看目标网页的源代码,找到所需内容对应的HTML标签。
3、在Chrome浏览器中,可在网页上右键选择“检查”,快速定位标签信息。
4、基本规则写法如下:
以@作为分隔符,将规则分为若干段。
每段规则通常包含三部分:第一部分为选择器类型(如class、id、tag),若使用children则直接获取所有子标签,无需后续两段;第二部分为具体名称;第三部分为位置索引(class或tag可能匹配多个元素,需指定序号,而id唯一,无需加位置)。
5、若不指定位置,则默认获取全部匹配项;使用!可排除特定位置,多个排除项用:分隔,%表示最后一个元素。
@符号后的最后一段用于指定提取内容类型,如text(文本)、textNodes、href(链接)、src(图片地址)、html(原始HTML)等。
6、若需适配多个不同网页结构,可用|或&连接规则:|表示优先采用首个成功获取的结果,&表示合并所有规则获取的内容。
7、如需对提取内容进行正则替换,可在规则末尾添加#及正则表达式。
8、示例:class.odd.0@tag.a.0@text|tag.dd.0@tag.h1@text#全文阅读
9、示例:class.odd.0@tag.a.0@text&tag.dd.0@tag.h1@text#全文阅读
常见问题
1、为什么首次安装后没有任何内容?
阅读App本身不提供小说内容,仅作为转码与聚合工具。首次使用需手动导入书源,用户可通过“开源阅读”公众号、QQ群或酷安评论区获取其他书友分享的书源文件。
2、正文出现缺字、漏字、内容缺失或排版错乱怎么办?
可能是净化规则误删了正常内容。建议先关闭“替换净化”功能并刷新页面,观察是否恢复正常。若关闭后显示正常,说明净化规则存在误判;若仍异常,请点击源链接对比原文,确认差异后再反馈问题。
3、目前支持哪些本地书籍格式?
当前版本支持TXT和EPUB两种主流电子书格式,方便用户导入本地藏书进行阅读。
应用截图
应用信息
- 厂商:kunfei
- 备案号:暂无
- 包名:com.ophone.reader.ui
- 版本:9.2.0
- MD5值:738D3EF52D47366961868721CAC8E96E
猜你喜欢
- 小说阅读免费版app
- 小说阅读免费版app
 小说阅读免费版app
小说阅读免费版app












同类热门












相关攻略








































专题推荐
-
炸金花 2026/4/15 17:46:59
-
火柴人战争遗产3内置菜单2026 2026/1/26 17:15:54
-
侠盗猎车手圣安地列斯版本合集 2026/1/26 17:15:31
-
恐怖躲猫猫2最新无广告 2026/1/26 17:15:16
-
公交车模拟器2022 2026/1/26 17:14:54
-
应用分身多开软件合集 2026/1/26 17:14:43
-
战地模拟器手机中文版 2026/1/26 17:14:27
-
保卫萝卜系列游戏大全 2026/1/26 17:14:14
-
热门二次元壁纸软件推荐 2026/1/26 17:14:02
-
橙光女性向养成游戏大全 2026/1/26 17:13:51